
在任何專案的開端,最重要的一步就是確認需求。無論是一棟高樓還是一個創新的 AI 應用,架構設計都是讓我們的想法落地成形的基礎。正如建築師需要一張藍圖,開發者也需要一個清晰的架構來指導專案的發展方向。
在設計 Suta.io 的時候,我們必須牢牢抓住兩大核心需求:
核心功能:自動生成教學文檔
想像一下,你手中有一份從未見過的程式碼,而你需要迅速理解並編寫一份教學文檔。這聽起來幾乎不可能完成,但這正是 Suta.io 的核心目標。用戶上傳程式碼後,系統將自動分析其結構和邏輯,並生成一份易於閱讀的步驟式教學文檔。這不僅是對程式碼的解析,更是對其背後邏輯的梳理與呈現。
用戶互動:AI 即時回應
用戶應該能夠與 AI 進行對話,提出問題,並獲得即時且準確的回應。這部分功能涉及到傳統的 Agent 與 RAG 技術。
然而,在這篇教學,我們會先將主要集中精力在第一個需求上,因為這是整個專案的基石。當我們成功解決了如何生成步驟式教學文件的問題後,第二個需求將自然進入開發的議程。
我們的目標是生成一份如同 Apple Developer 教學文件般精美且有條理的步驟式教學文檔 參見範例。這種文件的基本結構包含以下幾個部分:
(以下是範例圖)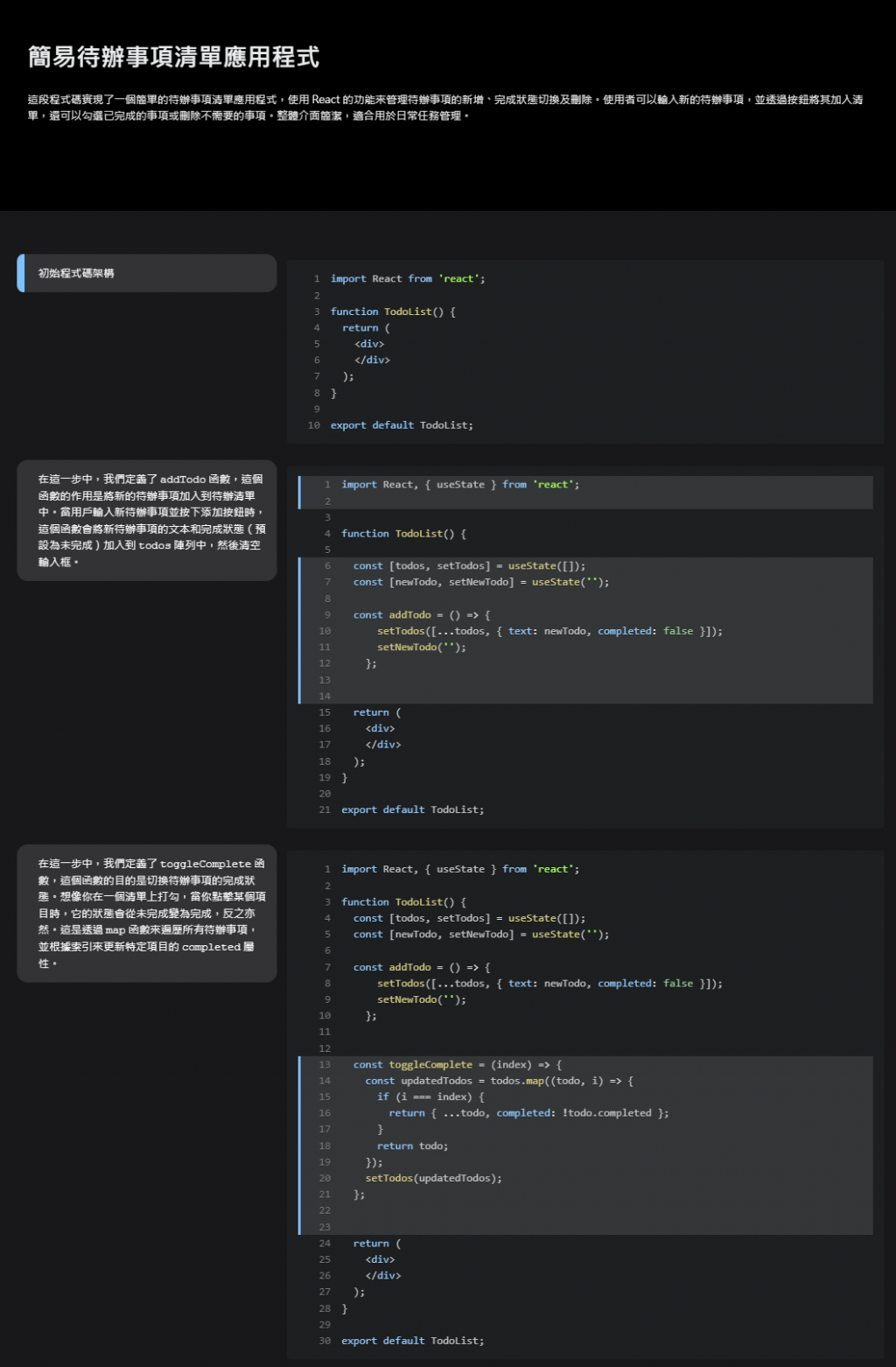
這聽起來非常直觀,但當你深入觀察這些文件時,你會發現 Apple 的教學文檔中,程式碼往往會用藍色高亮來表示變化部分。這並非簡單的字串可以實現。我們需要一個更複雜的資料結構來支持這種需求。
(以下是範例圖)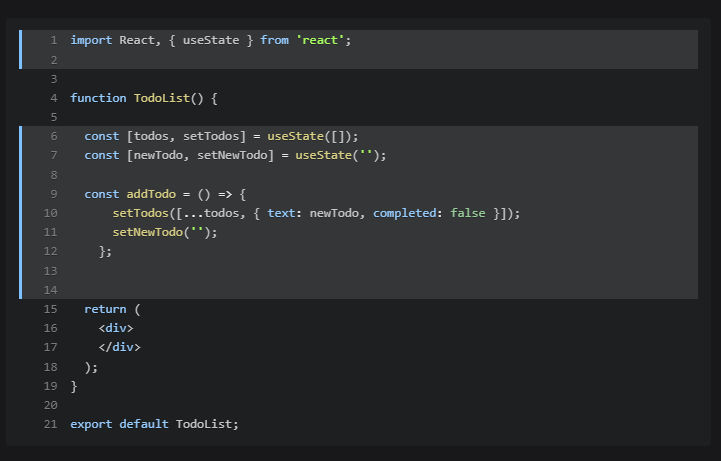
例如,我們可以使用一個陣列來記錄程式碼的每一行,每一行都是一個元素,並透過 added 屬性來標記這一行是否為新增程式碼。這樣我們就可以在前端實現高亮顯示的效果。
[
{
"text": "import React, { useState } from 'react';",
"added": true
},
{
"text": "function TodoList() {",
"added": false
}
]
因此,完整的教學文檔資料結構可以設計如下:
interface Tutorial {
title: string;
description: string;
steps: Step[];
}
interface Step {
description: string;
code: CodeLine[];
}
interface CodeLine {
text: string;
added: boolean;
}
這個結構雖然看似簡單,但已經能夠基本涵蓋我們所需的功能。當然,實際的 Suta.io 需求更複雜,導致資料結構更加豐富,不過這裡我們先不深入探討
當我們面對一個複雜的需求時,如自動生成步驟式教學文件,一個最直接的想法可能是將所有需求和資料結構直接丟給 ChatGPT,讓它生成整個 JSON 文件。這聽起來簡單、方便,但實際操作中,這種方法往往效果不佳。
處理能力的限制:當前的 AI 雖然強大,但它們仍然有處理字數的限制。當我們把過多的資訊一次性丟給 AI,它可能會無法精確地理解每一個細節,導致生成的結果不夠精確或不完整。
複雜度的挑戰:生成步驟式教學文件涉及多層次的邏輯和結構。如果只是讓 AI 一次性處理這些資料,它往往無法深入理解各個部分之間的關聯,這會導致生成的文件缺乏條理性或不符合我們的需求。
細節的丟失:AI 在處理大量資訊時,可能會忽略一些關鍵細節。這意味著生成的文件可能會遺漏重要的步驟或解釋不清某些關鍵部分,最終影響用戶的理解。
要解決這個問題,我們需要採取更具體、更細緻的方法。這裡,我們可以借用「分而治之」的策略,將一個大問題拆解成多個小問題,再來 AI 一次只處理一個小問題,即使是天才,在面對大量變因時也會感到束手無策。
拆分需求:首先,我們要把整體需求分解成多個小的、易於處理的部分。例如,先專注於生成文檔的標題和描述部分,然後再進一步生成每個步驟的說明和程式碼。這樣可以避免 AI 在處理過程中迷失方向。
逐步生成:我們可以讓 AI 先生成文檔的框架,確認其結構無誤後,再逐步填充具體的內容。這不僅可以確保每個部分都符合預期,還能讓我們隨時調整生成過程中的錯誤或不足之處。
測試驅動:定義好何謂成功,並且針對每一次 AI 回應結果進行測試,逐步迭代,直到達到我們的目標。
那當然,以上都只是針對實作的大概描述,接下來幾天,我會完整的介紹各個部分的實際層面,帶領大家一起實作出一個 AI 應用

